作者:拔剑少年
简书地址:https://www.jianshu.com/u/dad4d9675892
博客地址:https://it18monkey.github.io
转载请注明出处
什么是docker
我们先来看下官方给出的说法
Package Software into Standardized Units for Development, Shipment and Deployment
docker是一个工具,一个用于软件打包的工具。那这个打包工具有什么特殊的呢,他能将运行一个应用所需要的所有东西,包括程序代码、系统工具、系统库和系统设置都打成一个包。这个包被称之为容器。
我个人更倾向于将他描述为一个轻量级的虚拟机,因为它和虚拟机有着很多相似之处。
docker与虚拟机的区别
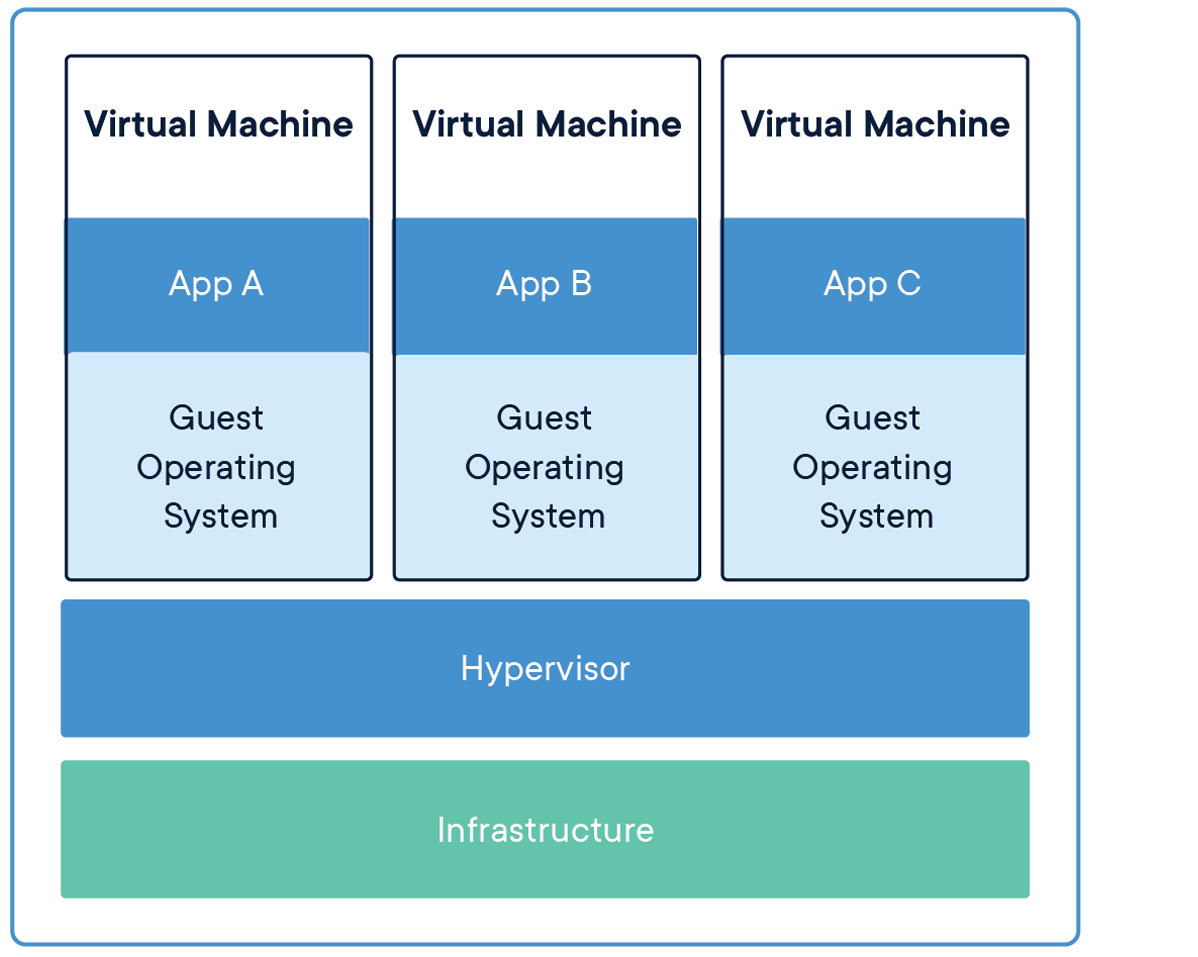
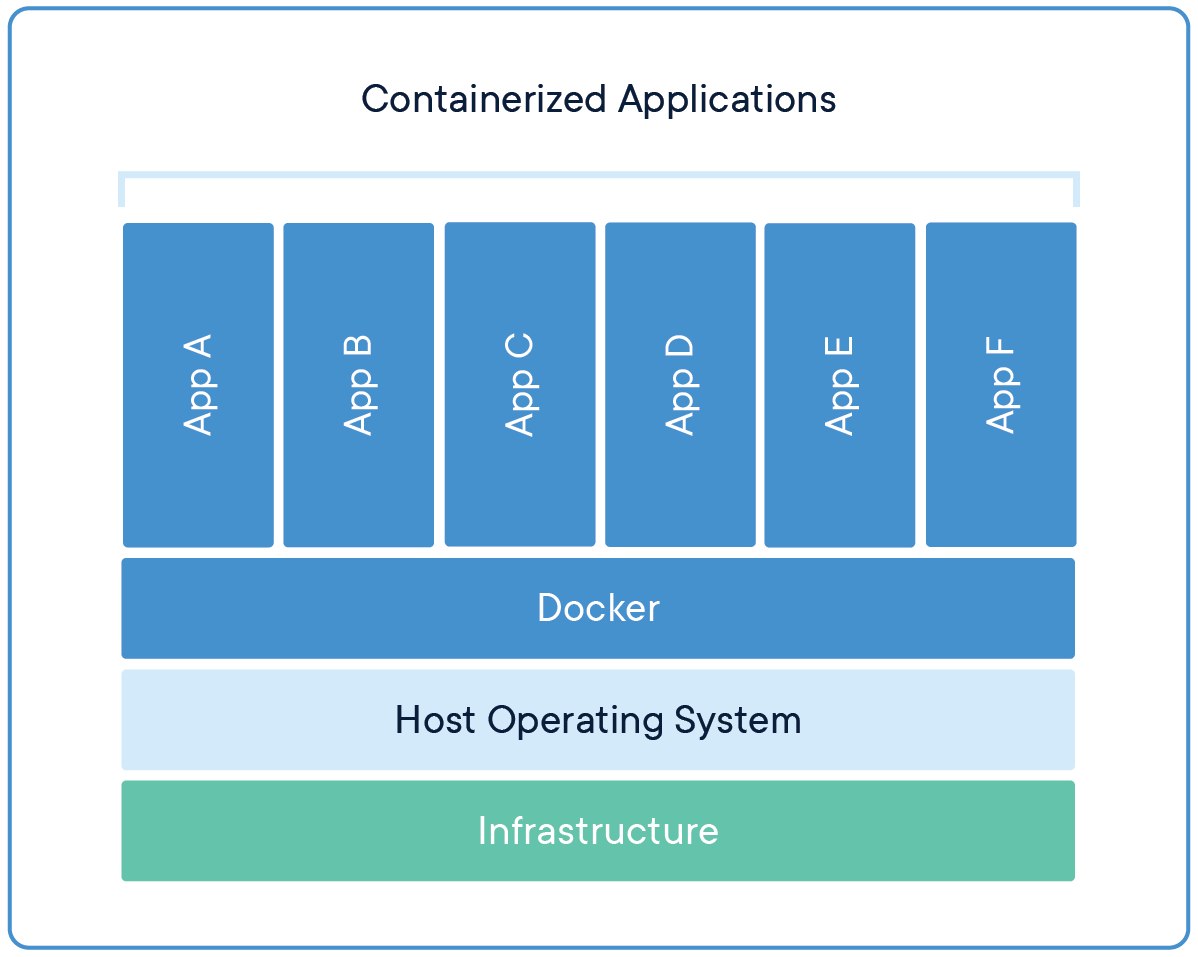
上面两幅图展示了用虚拟机和docker运行程序的大体结构。让我们从下往上来对比。
先看虚拟机这边:
最底层是某种类型的基础设施,可能是一台个人电脑,或者是服务器。往上,是一个名为hypervisor的虚拟机管理程序,在这之上运行客户操作系统,也就是虚拟系统,每个虚拟系统都是相互隔离的。然后,所有的应用程序都运行在虚拟系统上。这里提下,虚拟机也是可以运行在操作系统上的。它分为两种,一种直接运行在系统硬件上,创建硬件全仿真实例,被称为裸机型。一种运行在传统操作系统上,同样创建的是硬件全仿真实例,被称为“托管(宿主)”型。
再看docker这边:
最底层和虚拟机一样,是某种类型的基础设施,可能是一台个人电脑,或者是服务器。往上是一个宿主操作系统,可能是windows或者是linux。也就是说docker不能直接运行在系统硬件上。目前来说支持linux和windows。在这个宿主操作系统上,我们安装一个docker,而我们的应用程序全部都运行在docker上,由docker来统一管理。每个应用程序都是相互隔离的。
docker和虚拟机最大的区别就是他们的隔离级别不同。虚拟机是硬件级别的隔离,而docker只到进程级别。这一点也比较影响我们选择使用docker或是虚拟机。当然他们也不是互斥的,完全可以根据实际需要相互结合。
为什么要用docker
作为一种新兴的虚拟化方式,Docker 跟传统的虚拟化方式相比具有众多的优势。
- 更高效的利用系统资源
- 更快速的启动时间
- 一致的运行环境
- 持续交付和部署
- 更轻松的迁移
- 更轻松的维护和扩展
docker基本概念
- 镜像
我们都知道,操作系统分为内核和用户空间。对于 Linux 而言,内核启动后,会挂载 root 文件系统为其提供用户空间支持。而 Docker 镜像(Image),就相当于是一个 root 文件系统。比如官方镜像 ubuntu:18.04 就包含了完整的一套 Ubuntu 18.04 最小系统的 root 文件系统。
Docker 镜像是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。镜像不包含任何动态数据,其内容在构建之后也不会被改变。
- 容器
镜像( Image )和容器( Container )的关系,就像是面向对象程序设计中的类 和 实例 一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
- 仓库
镜像构建完成后,可以很容易的在当前宿主机上运行,但是,如果需要在其它服务器上使用这个镜像,我们就需要一个集中的存储、分发镜像的服务,DockerRegistry 就是这样的服务。一个 Docker Registry 中可以包含多个仓库( Repository );每个仓库可以包含多个标签( Tag );每个标签对应一个镜像。
通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本。我们可以通过 <仓库名>:<标签> 的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签。
Docker Registry 分为公开和私有两种,用户可以根据自己的需要搭配使用。
Docker常用命令
镜像仓库操作
docker login/logout
登陆/登出到一个Docker镜像仓库,如果未指定镜像仓库地址,默认为官方仓库 Docker Hub。
格式:
docker login [选项][SERVER] ,docker logout [选项][SERVER]。docker pull
从Docker Registry获取镜像。格式:
docker pull [选项][Docker Registry 地址[:端口号]/]仓库名[:标签]。docker push
将本地的镜像上传到镜像仓库,要先登陆到镜像仓库。格式:
docker push [选项] 仓库名[:标签]。docker search
从Docker Hub查找镜像。格式
docker search [选项] 关键字。
镜像操作
docker images
列出本地镜像。格式:
docker images [选项][仓库名[:标签]]。docker run
创建一个新的容器并运行一个命令。格式:
docker run [选项] 镜像名[命令][参数]。docker rmi
删除本地一个或多少镜像。格式:
docker rmi [选项] 镜像名[镜像名...]。docker build
使用 Dockerfile 创建镜像。格式:
docker build [选项] 路径 | URL | -。docker history
查看指定镜像的创建历史。格式:docker history [选项] 镜像名。
容器操作
- docker ps
列出容器。格式:docker ps [选项]。 docker inspect
获取容器/镜像的元数据。
docker inspect [选项] 名称|ID。docker start/stop/restart
docker start :启动一个或多个已经被停止的容器。格式:docker start [选项] 容器名[ [容器名...]]。
docker stop :停止一个运行中的容器。docker stop [选项] 容器名[ [容器名...]]。
docker restart :重启容器。docker restart [选项] 容器名[ [容器名...]]。- docker kill
杀掉一个运行中的容器。docker kill [选项] 容器名 [容器名...]。 - docker rm
删除一个或多个容器。docker rm [选项] 容器名[容器名...]
技术要点
UnionFS与镜像分层存储
所谓UnionFS就是把不同物理位置的目录合并mount到同一个目录中。UnionFS的一个最主要的应用是,把一张CD/DVD和一个硬盘目录给联合mount在一起,然后,你就可以对这个只读的CD/DVD上的文件进行修改(当然,修改的文件存于硬盘上的目录里)。
UnionFS主要有以下几种实现:aufs,overlayfs。下图展示了overlayfs的基本结构
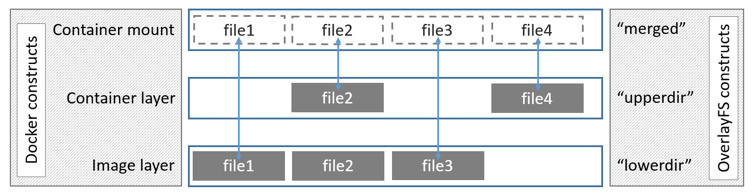
其中lower dirA / lower dirB目录和upper dir目录为来自底层文件系统的不同目录,用户可以自行指定,内部包含了用户想要合并的文件和目录,merge dir目录为挂载点。当文件系统挂载后,在merge目录下将会同时看到来自各lower和upper目录下的内容,并且用户也无法(无需)感知这些文件分别哪些来自lower dir,哪些来自upper dir,用户看见的只是一个普通的文件系统根目录而已(lower dir可以有多个也可以只有一个)。
虽然overlayfs将不同的各层目录进行合并,但是upper dir和各lower dir这几个不同的目录并不完全等价,存在层次关系。首先当upper dir和lower dir两个目录存在同名文件时,lower dir的文件将会被隐藏,用户只能看见来自upper dir的文件,然后各个lower dir也存在相同的层次关系,较上层屏蔽叫下层的同名文件。除此之外,如果存在同名的目录,那就继续合并(lower dir和upper dir合并到挂载点目录其实就是合并一个典型的例子)。
各层目录中的upper dir是可读写的目录,当用户通过merge dir向时其中一个来自upper dir的文件写入数据时,那数据将直接写入upper dir下原来的文件中,删除文件也是同理;而各lower dir则是只读的,在overlayfs挂载后无论如何操作merge目录中对应来自lower dir的文件或目录,lower dir中的内容均不会发生任何的改变。当用户想要往来自lower层的文件添加或修改内容时,overlayfs首先会的拷贝一份lower dir中的文件副本到upper dir中,后续的写入和修改操作将会在upper dir下的copy-up的副本文件中进行,lower dir原文件被隐藏。
以上就是overlayfs最基本的特性,简单的总结为以下3点:
(1)上下层同名目录合并;
(2)上下层同名文件覆盖;
(3)lower dir文件写时拷贝。
这三点对用户都是无感知的。
Linux Namespace
为了提供更加精细的资源分配管理机制,Linux给出了namespace解决方法。Docker利用这一技术实现了容器运行环境的隔离。
linux内核实现了六种namespace。列表如下:
| namespace | 引入的相关内核版本 | 被隔离的全局系统资源 | 在容器语境下的隔离效果 |
|---|---|---|---|
| Mount namespaces | Linux 2.4.19 | 文件系统挂接点 | 每个容器能看到不同的文件系统层次结构 |
| UTS namespaces | Linux 2.6.19 | 主机名和域名 | 每个容器可以有自己的 主机名和 域名 |
| IPC namespaces | Linux 2.6.19 | 特定的进程间通信资源,包括System V IPC和 POSIX message queues | 每个容器有其自己的 System V IPC 和 POSIX 消息队列文件系统,因此,只有在同一个 IPC namespace 的进程之间才能互相通信 |
| PID namespaces | Linux 2.6.24 | 进程 ID 数字空间 | 每个 PID namespace 中的进程可以有其独立的 PID; 每个容器可以有其 PID 为 1 的root 进程;也使得容器可以在不同的宿主机之间迁移,因为 namespace 中的进程 ID 和 宿主机无关了。这也使得容器中的每个进程有两个PID:容器中的 PID 和宿主机上的 PID。 |
| Network namespaces | 始于Linux 2.6.24 完成于 Linux 2.6.29 | 网络相关的系统资源 | 每个容器用有其独立的网络设备,IP 地址,IP 路由表,/proc/net 目录,端口号等等。这也使得一个 宿主机 上多个容器内的同一个应用都绑定到各自容器的 80 端口上。 |
| User namespaces | 始于 Linux 2.6.23 完成于 Linux 3.8) | 用户和组 ID 空间 | 在 user namespace 中的进程的用户和组 ID 可以和在宿主机上不同; 每个 container 可以有不同的 user 和 group id;一个宿主机上的非特权用户可以成为 user namespace 中的特权用户; |
Linux namespace 的概念说简单也简单说复杂也复杂。简单来说,我们只要知道,处于某个 namespace 中的进程,能看到独立的它自己的隔离的某些特定系统资源;复杂来说,可以去看看 Linux 内核中实现 namespace 的原理。
Linux CGroups
Docker 容器使用 linux namespace 来隔离其运行环境,使得容器中的进程看起来就像爱一个独立环境中运行一样。但是,光有运行环境隔离还不够,因为这些进程还是可以不受限制地使用系统资源,比如网络、磁盘、CPU以及内存等。因此,为了让容器中的进程更加可控,Docker 使用 Linux cgroups 来限制容器中的进程允许使用的系统资源。
目前 docker 已经几乎支持了所有的 cgroups 资源,可以限制容器对包括 network,device,cpu 和memory 在内的资源的使用
我们可以通过给docker run 命令传参来控制分配容器的资源。Docker run 命令中 cgroups 相关命令如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24block IO:
--blkio-weight value Block IO (relative weight), between 10 and 1000
--blkio-weight-device value Block IO weight (relative device weight) (default [])
--cgroup-parent string Optional parent cgroup for the container
CPU:
--cpu-percent int CPU percent (Windows only)
--cpu-period int Limit CPU CFS (Completely Fair Scheduler)period
--cpu-quota int Limit CPU CFS (Completely Fair Scheduler) quota
-c, --cpu-shares int CPU shares (relative weight)
--cpuset-cpus string CPUs in which to allow execution (0-3, 0,1)
--cpuset-mems string MEMs in which to allow execution (0-3, 0,1)
Device:
--device Add a host device to the container
--device-cgroup-rule Add a rule to the cgroup allowed devices list
--device-read-bps Limit read rate (bytes per second) from a device
--device-read-iops Limit read rate (IO per second) from a device
--device-write-bps Limit write rate (bytes per second) to a device
--device-write-iops Limit write rate (IO per second) to a device
Memory:
--kernel-memory string Kernel memory limit
--memory , -m Memory limit
--memory-reservation Memory soft limit
--memory-swap Swap limit equal to memory plus swap: ‘-1’ to enable unlimited swap
--memory-swappiness Tune container memory swappiness (0 to 100)

